Googlescraper
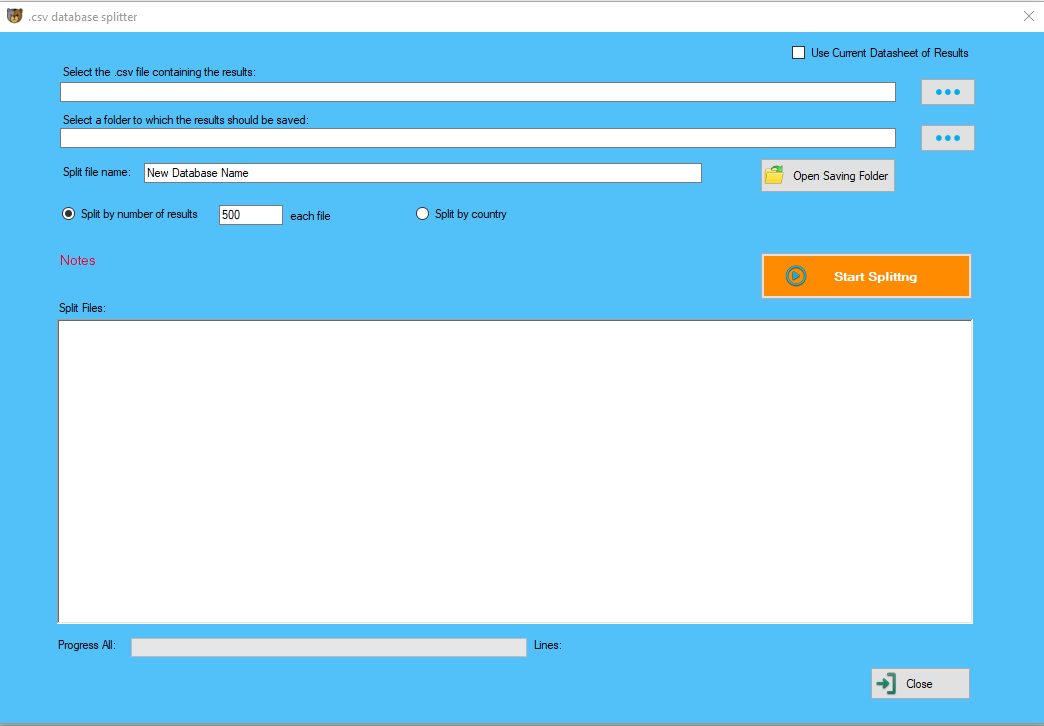
Content
- Search Engine Scraping
- Need To Scrape Google Search Results? Get Your Top-a hundred Results For Any Keyword!
- Skill & Expertise Of Deep Crawling & Intelligent Extraction Of Data From Different Search Engines
- Is There Any Python Lib To Scrape Search Engine(s) Results?
- Googlescraper 0.2.4
- Googlescraper - Scraping Search Engines Professionally
Search Engine Scraping
This is about the one factor the webbrowser module can do. Even so, the open() operate does make some attention-grabbing issues attainable.
Need To Scrape Google Search Results? Get Your Top-one hundred Results For Any Keyword!
For example, it’s tedious to copy a street handle to the clipboard and convey up a map of it on Google Maps. You may take a couple of steps out of this task by writing a easy script to automatically launch the map in your browser utilizing the contents of your clipboard.
Skill & Expertise Of Deep Crawling & Intelligent Extraction Of Data From Different Search Engines
Web scraping takes the ache out of this expertise by automating the whole process. I want to scrape hyperlink from totally different search engine for my search question in python.
Is There Any Python Lib To Scrape Search Engine(s) Results?
If you’re new to Python or the world of laptop vision and picture processing, I would recommend you work by way of my book, Practical Python and OpenCV that will help you learn the fundamentals. The output/full listing of images was obtained by working the scripts. I’m unsure what you mean by the “snazzy viewer”, but that's only a constructed-in file previewer in Mac OS. Was in a position to create and run the Time Magazine cover scraper on my Mac.
Googlescraper 0.2.4
Web scrapers are extra complicated than this simplistic illustration. They have a number of modules that perform different features.
Googlescraper - Scraping Search Engines Professionally
Web scraping is used in almost all fields corresponding to value monitoring, real property, SEO monitoring, and placement intelligence. Copying an inventory of contacts from an internet directory is an instance of “net scraping”. But copying and pasting particulars from an online page into an Excel spreadsheet works for only a small amount of data and it requires a major period of time. The strategy of coming into a web site and extracting knowledge in an automatic fashion can be usually known as "crawling". Search engines like Google, Bing or Yahoo get virtually all their information from automated crawling bots. Scraping with low degree http libraries similar to urllib.request or requests modules. Update the next settings in the GoogleScraper configuration file scrape_config.py to your values. This project is again to stay after two years of abandonment. In the approaching weeks, I will take a while to update all functionality to the newest developments. This encompasses updating all Regexes and modifications in search engine behavior. After a couple of weeks, you can expect this project to work again as documented right here. A module to scrape and extract hyperlinks, titles and descriptions from various search engines like google and yahoo.
You’ll discover ways to scrape static net pages, dynamic pages (Ajax loaded content material), iframes, get specific HTML parts, how to deal with cookies, and rather more stuff. You will also study scraping traps and tips on how to keep away from them.
ash your Hands and Stay Safe during Coronavirus (COVID-19) Pandemic - JustCBD https://t.co/XgTq2H2ag3 @JustCbd pic.twitter.com/4l99HPbq5y
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
Scrapy Open supply python framework, not dedicated to look engine scraping however regularly used as base and with a large number of customers. When developing a search engine scraper there are several current instruments and libraries out there that may either be used, extended or just analyzed to be taught from. When developing a scraper for a search engine virtually Data Extraction Tool with AI any programming language can be used however depending on efficiency requirements some languages might be favorable. An instance of an open source scraping software which makes use of the above mentioned strategies is GoogleScraper. This framework controls browsers over the DevTools Protocol and makes it exhausting for Google to detect that the browser is automated. If there are no command line arguments, this system will assume the handle is stored on the clipboard. You can get the clipboard content with pyperclip.paste() and retailer it in a variable named address. Finally, to launch a web browser with the Google Maps URL, call webbrowser.open(). We’ll make knowledge extraction simpler by constructing an online scraper to retrieve stock indices mechanically from the Internet. While I’m actually to help point you in the proper course, I cannot write custom code snippets. The requests and BeautifulSoup modules are nice as long as you can work out the URL you need to pass to requests.get(). Or maybe the web site you need your program to navigate requires you to log in first. The selenium module will give your applications the power to perform such subtle tasks. At this point, the picture file of the comic is saved within the res variable. You want to write this picture knowledge to a file on the onerous drive. 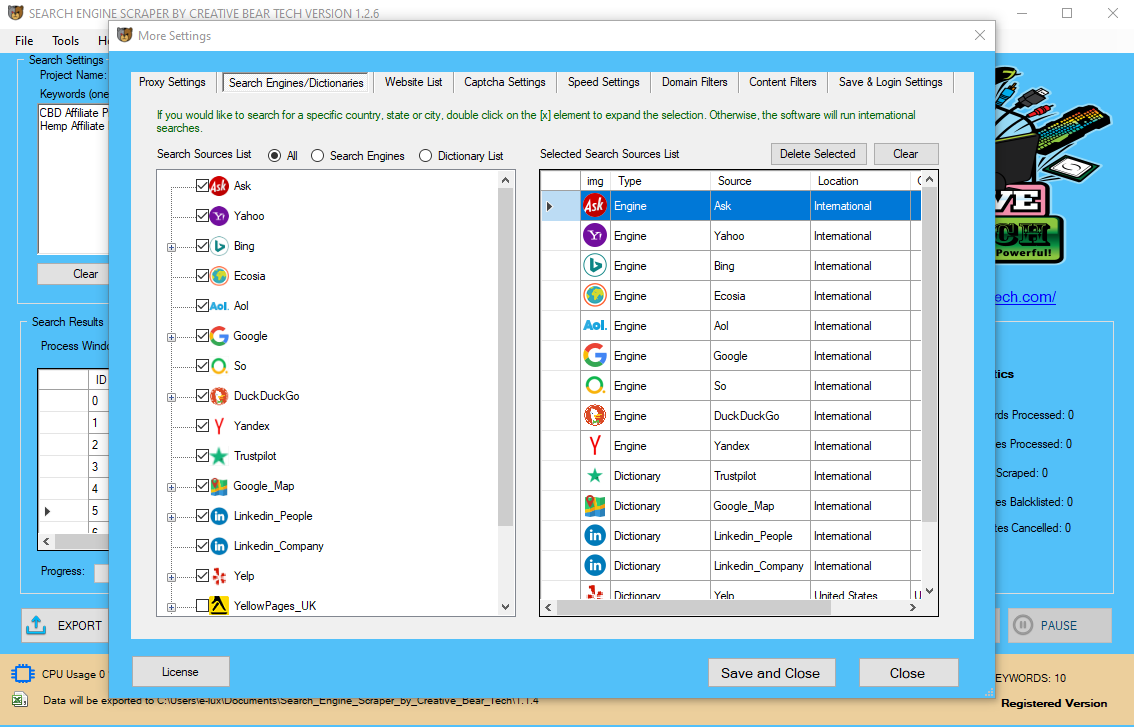 The high quality of IPs, strategies of scraping, keywords requested and language/country requested can greatly have an effect on the attainable most price. The extra keywords a user must scrape and the smaller the time for the job the more difficult scraping shall be and the more developed a scraping script or tool needs to be.
The high quality of IPs, strategies of scraping, keywords requested and language/country requested can greatly have an effect on the attainable most price. The extra keywords a user must scrape and the smaller the time for the job the more difficult scraping shall be and the more developed a scraping script or tool needs to be.
- Ultimately when the createDownload operate runs, your browser will set off a obtain.
- The selenium module lets Python instantly management the browser by programmatically clicking hyperlinks and filling in login info, nearly as though there's a human user interacting with the web page.
- We attempt to obtain the picture file right into a variable, r , which holds the binary file (together with HTTP headers, etc.) in memory briefly (Line 25).
- The code in the for loop writes out chunks of the image data (at most 100,000 bytes each) to the file and then you definitely close the file.
- Remember from earlier on this chapter that to save recordsdata you’ve downloaded using Requests, you should loop over the return worth of the iter_content() technique.
- Depending in your browser settings, your download could go to your default obtain location or you might be prompted to pick out a reputation and location on your picture URLs file download.
I am looking for a python library to scrape outcomes from search engines like google (google, yahoo, bing, and so forth). This is a selected type of web scraping, Data Crawling dedicated to search engines solely. It could be nice if I might merely type a search time period on the command line and have my laptop automatically open a browser with all the top search results in new tabs. This code makes use of requests.get() to download the main web page from the No Starch Press web site after which passes the text attribute of the response to bs4.BeautifulSoup(). The BeautifulSoup object that it returns is stored in a variable named noStarchSoup. ), I open the primary several links in a bunch of latest tabs to learn later. I search Google typically enough that this workflow—opening my browser, looking for a subject, and middle-clicking several links one by one—is tedious.
JustCBD CBD Gummies - CBD Gummy Bears https://t.co/9pcBX0WXfo @JustCbd pic.twitter.com/7jPEiCqlXz
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
Compared to Scarpy, i felt the ‘Beautiful Soup’ library (along with Requests module) a neater tool for scarping pictures from websites. Let’s do something hands-on before we get into net pages constructions and XPaths. The efficiency of information retrieval is way greater than scraping webpages. For instance, check out Facebook Graph API, which might help you get hidden data which isn't proven on Facebook webpages. Then we modify the info extraction code into a for loop, which will course of the URLs one by one and store all the info right into a variable knowledge in tuples. You can then compile this knowledge for research, analysis, or any variety of purposes. Search engineData Scrapingis the method ofCrawling URLs,descriptions, Keyword, Title and Display Ads data from search engines such asGoogle,BingorYahoo. Some parts have an id attribute that is used to uniquely determine the component within the page. You will often instruct your applications to seek out an element by its id attribute, so figuring out a component’s id attribute using the browser’s developer tools is a common task in writing internet scraping packages.
Canada Vape Shop Database
— Creative Bear Tech (@CreativeBearTec) March 29, 2020
Our Canada Vape Shop Database is ideal for vape wholesalers, vape mod and vape hardware as well as e-liquid manufacturers and brands that are looking to connect with vape shops.https://t.co/0687q3JXzi pic.twitter.com/LpB0aLMTKk
Kick Start your B2B sales with the World's most comprehensive and accurate Sports Nutrition Industry B2B Marketing List.https://t.co/NqCAPQqF2i
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Contact all sports nutrition brands, wholesalers and manufacturers from all over the world in a click of a button. pic.twitter.com/sAKK9UmvPc
You can construct web scrapers in almost any programming language. It is less complicated with Scripting languages corresponding to Javascript (Node.js), PHP, Perl, Ruby, or Python. Many firms build their very own net scraping departments but different companies use Web Scraping providers. This kind of block is likely triggered by an administrator and only occurs if a scraping software is sending a really high number of requests. In the previous years search engines like google have tightened their detection techniques nearly month by month making it increasingly troublesome to dependable scrape as the developers have to experiment and adapt their code often. Google is the by far largest search engine with most users in numbers in addition to most income in creative commercials, this makes Google the most important search engine to scrape for search engine optimization related firms. This means, you only have to copy the tackle to a clipboard and run the script, and the map shall be loaded for you. Now, if the shape is populated with knowledge, then there's a big chance that it was carried out by an internet scraper, and the despatched kind shall be blocked. Web varieties that are coping with account logins and creation show a high menace to safety if they are an easy target for casual scraping. So, for many website house owners, they will use these forms to restrict scraper access to their websites. One of the essential methods of fixing lots of scraping points is handling cookies correctly. Your browser runs JavaScript and hundreds any content material usually, and that what we will do using our second scraping library, which is called Selenium. Imagine that you just wish to scrape some hyperlinks that match a particular pattern like inside hyperlinks or particular exterior links or scrape some pictures that reside in a specific path. This code will get all span, anchor, and image tags from the scraped HTML. You may marvel why I should scrape the web and I even have Google? The benefits of outsourcing internet scraping requirements are you could concentrate on your projects. Companies that present web scraping services like ScrapeHero can help you save time. As more and more of our enterprise activities and our lives are being spent on-line there are infinite makes use of for internet scrapers. To scrape a search engine successfully the 2 main factors are time and amount. The third layer of defense is a longterm block of the complete community phase. The most disappointing factor while scraping a website is the info not seen throughout viewing the output even it’s visible in the browser. Or the webserver denies a submitted type that sounds perfectly fine. Or even worse, your IP gets blocked by a website for nameless reasons. We will make a very simple scraper to scrape Reddit’s prime pages and extract the title and URLs of the hyperlinks shared. Extracting information is the method of taking the raw scraped information that is in HTML format and extracting and parsing the meaningful data elements. In some circumstances extracting data may be simple similar to getting the product details from an internet web page or it can get harder corresponding to retrieving the best info from complicated documents. At the bottom of your code, add the code for writing data to a csv file. If you’re an avid investor, getting closing prices daily is usually a pain, especially when the knowledge you want is discovered throughout several webpages.