5 Best Web Scraping Tools To Extract Online Data
Food And Beverage Industry Email Listhttps://t.co/8wDcegilTq pic.twitter.com/19oewJtXrn
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Content
Making Web Data Extraction
In 2000, Salesforce and eBay launched their very own API, with which programmers were enabled to access and download some of the data out there to the general public. Since then, many websites supply internet APIs for folks to entry their public database. There are methods that some web sites use to prevent internet scraping, similar to detecting and disallowing bots from crawling (viewing) their pages.
Easy And Accessible For Everyone
This system makes it possible to tailor data extraction to different website constructions. Our goal is to make net data extraction so simple as attainable. Configure scraper by simply pointing and clicking on components. Some sites may be using software that attempts to stop web scrapers. Depending how subtle these protections are, you might run into further challenges.
Extract Data From Dynamic
It also permits you to seize photographs and PDFs into a feasible format. Besides, it covers the complete net extraction lifecycle from information extraction to evaluation inside one platform. The Advanced modehas more flexibility evaluating the other mode. This permits users to configure and edit the workflow with more choices. Advance mode is used for scraping more advanced websites with a massive amount of knowledge.
Web Sites
In case you wish to use the data miner on a variety of web sites like Google, ebay, LinkedIn, and lots of extra such web sites, you'll need to login first. The data thus scraped can be either copied to the clipboard, and downloaded as CSV. Then click the export data as CSV button which downloads the scraped information in CSV format.
Explode your B2B sales with our Global Vape Shop Database and Vape Store Email List. Our Global Vape Shop Database contains contact details of over 22,000 cbd and vape storeshttps://t.co/EL3bPjdO91 pic.twitter.com/JbEH006Kc1
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Export Data In Csv, Xlsx And Json
If you’re an avid investor, getting closing prices every single day could be a pain, especially when the knowledge you need is found throughout several webpages. We’ll make information extraction easier by building an internet scraper to retrieve stock indices mechanically from the Internet. Web scraping (additionally termed web information extraction, display scraping, or internet harvesting) is a way of extracting data from the websites. It turns unstructured information into structured knowledge that can be stored into your native computer or a database.
Global Hemp Industry Database and CBD Shops B2B Business Data List with Emails https://t.co/nqcFYYyoWl pic.twitter.com/APybGxN9QC
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Formats
The web scraper provides 20 scraping hours free of charge and will price $29 per month. CloudScrape supports data collection from any website and requires no download identical to Webhose. Darcy Ripper makes it attainable for you to view each step of your download process. This means you could visualize any URL that's being accessed or any resource that has been processed/downloaded. In this tutorial, you’ll build a web scraper that fetches Software Developer job listings from the Monster job aggregator website. Your web scraper will parse the HTML to pick out the relevant items of data and filter that content for particular phrases. In distinction, whenever you try to get the information you need manually, you would possibly spend plenty of time clicking, scrolling, and looking out. It supplies a browser-based editor to set up crawlers and extract knowledge in actual-time. You can save the collected knowledge on cloud platforms like Google Drive and Box.net or export as CSV or JSON. Using an internet scraping device, one can also obtain solutions for offline studying or storage by accumulating data from multiple websites (including StackOverflow and extra Q&A web sites). This reduces dependence on active Internet connections as the sources are available in spite of the provision of Internet access.
Kick Start your B2B sales with the World's most comprehensive and accurate Sports Nutrition Industry B2B Marketing List.https://t.co/NqCAPQqF2i
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Contact all sports nutrition brands, wholesalers and manufacturers from all over the world in a click of a button. pic.twitter.com/sAKK9UmvPc
Use our REST API. Download the extracted knowledge in Excel and JSON. Easily instruct ParseHub to go looking through types, open drop downs, login to web sites, click on on maps and handle websites with infinite scroll, tabs and pop-ups to scrape your data. ParseHub is an intuitive and straightforward to learn knowledge scraping software. There are a variety of tutorials to get you began with the fundamentals after which progress on to extra superior extraction projects. It's also straightforward to start out on the free plan and then migrate up to the Standard and Professional plans as required. Boolean, if true scraper will proceed downloading sources after error occurred, if false - scraper will finish course of and return error. Boolean, if true scraper will follow hyperlinks in html information. Don't neglect to set maxRecursiveDepth to avoid infinite downloading. Your browser will diligently execute the JavaScript code it receives again from a server and create the DOM and HTML for you locally. However, doing a request to a dynamic web site in your Python script will not give you the HTML page content. By now, you’ve successfully harnessed the ability and consumer-friendly design of Python’s requests library. With only some traces of code, you managed to scrape the static HTML content from the net and make it out there for additional processing. It retrieves the HTML data that the server sends again and shops that information in a Python object. The efficiency of information retrieval is far larger than scraping webpages. For example, take a look at Facebook Graph API, which may help you get hidden information which is not shown on Facebook webpages. Web scraping mechanically extracts data and presents it in a format you possibly can easily make sense of. In this tutorial, we’ll concentrate on its applications in the monetary market, however web scraping can be used in all kinds of situations. 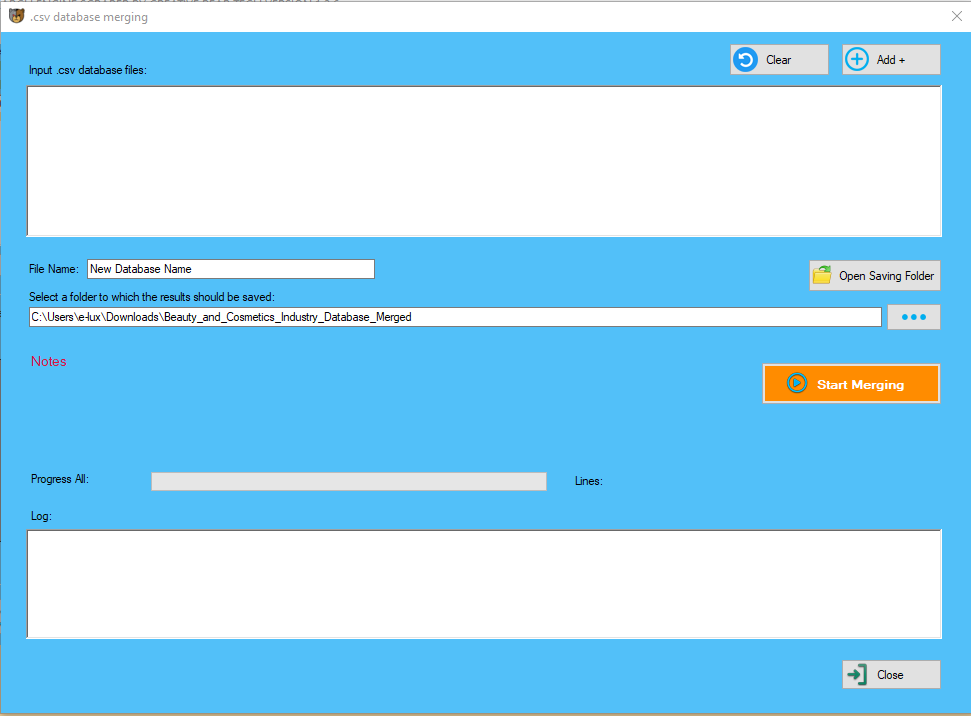 WP Scraper makes it simple with an easy to use visible interface on your WordPress site. The freeware provides anonymous internet proxy servers for internet scraping. These software search for new information manually or routinely, fetching the brand new or updated knowledge and storing them for your quick access. For example, one might gather data about products and their prices from Amazon using a scraping device. One of the first major exams of display screen scraping concerned American Airlines (AA), and a firm called FareChase. The airline argued that FareChase's websearch software program trespassed on AA's servers when it collected the publicly obtainable knowledge. By June, FareChase and AA agreed to settle and the appeal was dropped. The easiest form of web scraping is manually copying and pasting knowledge from a web page into a text file or spreadsheet. It is an interface that makes it much simpler to develop a program by offering the constructing blocks.
WP Scraper makes it simple with an easy to use visible interface on your WordPress site. The freeware provides anonymous internet proxy servers for internet scraping. These software search for new information manually or routinely, fetching the brand new or updated knowledge and storing them for your quick access. For example, one might gather data about products and their prices from Amazon using a scraping device. One of the first major exams of display screen scraping concerned American Airlines (AA), and a firm called FareChase. The airline argued that FareChase's websearch software program trespassed on AA's servers when it collected the publicly obtainable knowledge. By June, FareChase and AA agreed to settle and the appeal was dropped. The easiest form of web scraping is manually copying and pasting knowledge from a web page into a text file or spreadsheet. It is an interface that makes it much simpler to develop a program by offering the constructing blocks.
- Outwit hub is a Firefox extension, and it may be easily downloaded from the Firefox add-ons store.
- Once installed and activated, you can scrape the content from web sites immediately.
- It has an excellent "Fast Scrape" options, which rapidly scrapes information from an inventory of URLs that you just feed in.
- You can check with our guide on utilizing Outwit hub to get began with net scraping using the device.
Extracted data will be hosted on Dexi.io’s servers for 2 weeks before archived, or you can immediately export the extracted knowledge to JSON or CSV recordsdata. It presents paid providers to meet your wants for getting actual-time information. It provides a visible setting for finish-customers to design and customize the workflows for harvesting knowledge. 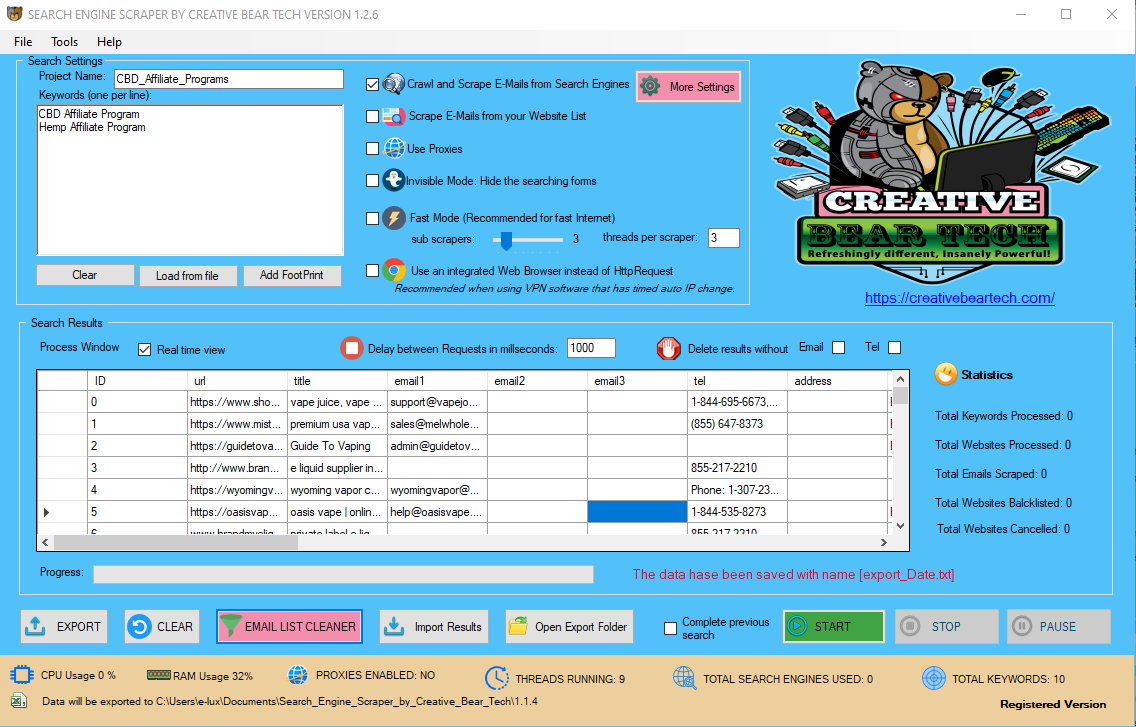 Web pages are built utilizing textual content-primarily based mark-up languages (HTML and XHTML), and regularly contain a wealth of useful knowledge in text type. However, most net pages are designed for human finish-customers and never for ease of automated use. As a end result, specialized tools and software program have been developed to facilitate the scraping of internet pages. Then we change the info extraction code right into a for loop, which can process the URLs one by one and retailer all the info into a variable knowledge in tuples. A user with primary scraping skills will take a wise transfer by using this model-new function that enables him/her to show web pages into some structured knowledge instantly. The Task Template Mode solely takes about 6.5 seconds to tug down the information behind one page and allows you to download the data to Excel. So, it would be nice should you could download a copy of the code and sources of the web site to manipulate it regionally right? Thanks to a reasonably helpful script that uses Puppeteer, this can be simply done within just minutes (and seconds after its implementation). In this article, we'll explain you how to simply implement your individual web site cloner with Node.js. The software program allows you to download entire web sites and download web pages to your local onerous drive. But now, with WebSite eXtractor, you'll be able to download entire web sites (or elements of them) in one go to your computer. You can then view the entire web site offline at your leisure – and you may whiz via the saved pages at lightning speed.
Web pages are built utilizing textual content-primarily based mark-up languages (HTML and XHTML), and regularly contain a wealth of useful knowledge in text type. However, most net pages are designed for human finish-customers and never for ease of automated use. As a end result, specialized tools and software program have been developed to facilitate the scraping of internet pages. Then we change the info extraction code right into a for loop, which can process the URLs one by one and retailer all the info into a variable knowledge in tuples. A user with primary scraping skills will take a wise transfer by using this model-new function that enables him/her to show web pages into some structured knowledge instantly. The Task Template Mode solely takes about 6.5 seconds to tug down the information behind one page and allows you to download the data to Excel. So, it would be nice should you could download a copy of the code and sources of the web site to manipulate it regionally right? Thanks to a reasonably helpful script that uses Puppeteer, this can be simply done within just minutes (and seconds after its implementation). In this article, we'll explain you how to simply implement your individual web site cloner with Node.js. The software program allows you to download entire web sites and download web pages to your local onerous drive. But now, with WebSite eXtractor, you'll be able to download entire web sites (or elements of them) in one go to your computer. You can then view the entire web site offline at your leisure – and you may whiz via the saved pages at lightning speed.
Global Vape And CBD Industry B2B Email List of Vape and CBD Retailers, Wholesalers and Manufacturershttps://t.co/VUkVWeAldX
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Vape Shop Email List is the secret sauce behind the success of over 500 e-liquid companies and is ideal for email and newsletter marketing. pic.twitter.com/TUCbauGq6c
Just install the software after which browse to the web site from which you want to scrape the data. IRobot is an effective software which can be utilized for screen scraping. In order to know how to scrape an internet site utilizing this software, you have to undertake the next steps. Under the following page navigation tab, you possibly can select the choice to mechanically navigate paginated pages. Here set the choice of subsequent web page element Xpath, set the URL or click on, and set the auto advance wait time. For example, you can add variables within the script, that will prompt you to enter values if you start operating the extension. The extension is so popular that you can simply find scripts on the internet for performing well-liked Top Lead Generation Software - 2020 Reviews & Pricing tasks. Then the scraper window is displayed the place the entire related data from the table is displayed showing the selectors, columns and filters. GetData.IO is an easy Chrome extension which can be used to scrape data from the websites. In this post, we’re itemizing the use instances of web scraping instruments and the highest 10 web scraping instruments to gather info, with zero coding. Build scrapers, scrape sites and export information in CSV format directly from your browser. Use Web Scraper Cloud to export data in CSV, XLSX and JSON formats, entry it through API, webhooks or get it exported via Dropbox. Web Scraper allows you to build Site Maps from several types of selectors. 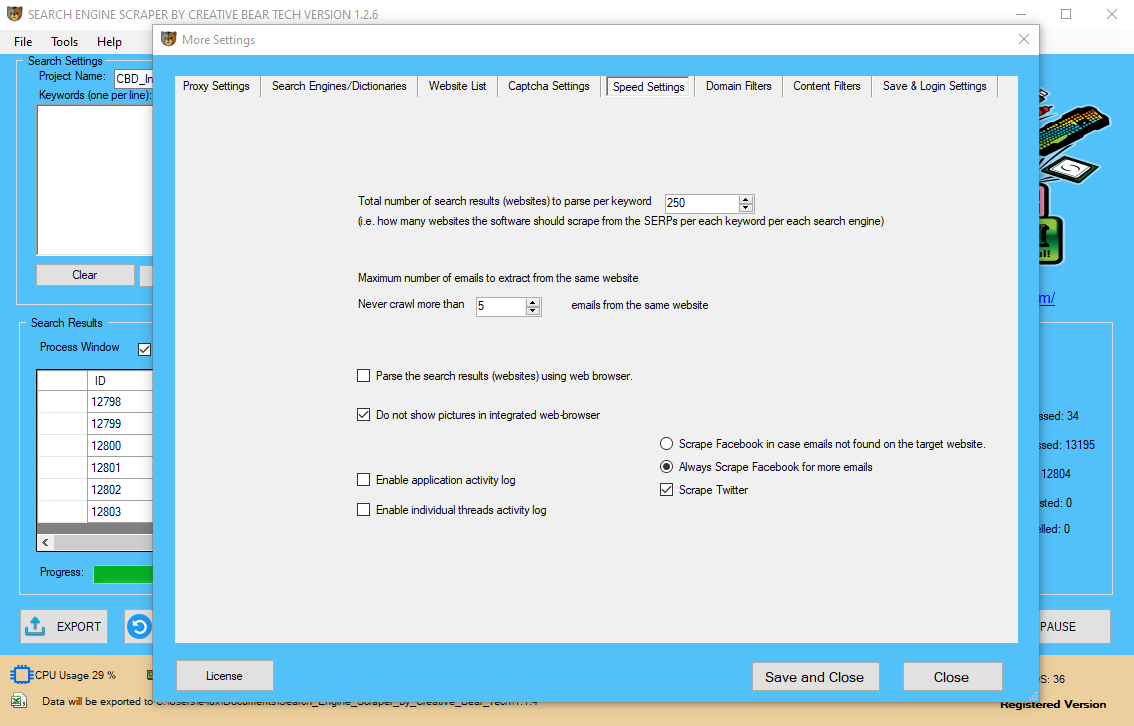 Some programmers who create scraper sites may buy a lately expired area name to reuse its web optimization power in Google. Whole companies concentrate on understanding all[citation needed] expired domains and utilising them for his or her historical rating capability exist. Doing so will permit SEOs to utilize the already-established backlinks to the domain name. Another kind of scraper will pull snippets and textual content from websites that rank high for keywords they have focused. Now let us see how to extract data from the Flipkart web site utilizing Python. Most of the online migration software program obtainable is tough to use and desires advanced knowledge. Make custom extraction queries to scrape any information from any site. If you’ve written the code alongside this tutorial, then you'll be able to already run your script as-is. The filtered outcomes will only present links to job alternatives that embody python in their title. You can use the identical square-bracket notation to extract other HTML attributes as nicely. In order to use this characteristic you should have a information of the Regular Expressions. Here you can even choose the extraction sample and apply the identical to be able to obtain particular information. DEiXTo is a simple and feature rich internet data extracting software. It was originally out there as an extension for Firefox, however is now available for Chrome and IE as nicely. This is a very simple extension that permits you to “educate” what to scrape and the way to scrape. A frequent use case is to fetch the URL of a link, as you did above. Run the above code snippet and also you’ll see the textual content content material displayed. Since you’re now working with Python strings, you'll be able to .strip() the superfluous whitespace. This is especially true should you need massive amounts of data from web sites that are often updated with new content. Thankfully, the world presents different methods to use that surfer’s mindset! Instead of trying at the job web site every day, you need to use Python to help automate the repetitive parts of your job search. Automated web scraping can be a answer to hurry up the data assortment course of. You write your code as soon as and it will get the data you want many instances and from many pages. Array of objects to download, specifies selectors and attribute values to pick files for downloading. Scraper makes use of cheerio to pick out html parts so selector could be any selector that cheerio supports. String, absolute path to directory where downloaded information will be saved. How to download web site to present listing and why it's not supported by default - verify right here. In offline browser mode, it downloads web sites for offline viewing and translate all the inner links to native links. Unlike most some other tools, this feature makes it attainable so that you can notice if one thing isn't working as you anticipated it and you might cease the method and remedy the problem. Besides the actual-time presentation of the download course of, Darcy is able to remember and provide to you statistics relating to all your download processes. Plus, you may copy web site downloaded to knowledge storage units, like USB sticks, CD or DVD; the copied websites will work.
Some programmers who create scraper sites may buy a lately expired area name to reuse its web optimization power in Google. Whole companies concentrate on understanding all[citation needed] expired domains and utilising them for his or her historical rating capability exist. Doing so will permit SEOs to utilize the already-established backlinks to the domain name. Another kind of scraper will pull snippets and textual content from websites that rank high for keywords they have focused. Now let us see how to extract data from the Flipkart web site utilizing Python. Most of the online migration software program obtainable is tough to use and desires advanced knowledge. Make custom extraction queries to scrape any information from any site. If you’ve written the code alongside this tutorial, then you'll be able to already run your script as-is. The filtered outcomes will only present links to job alternatives that embody python in their title. You can use the identical square-bracket notation to extract other HTML attributes as nicely. In order to use this characteristic you should have a information of the Regular Expressions. Here you can even choose the extraction sample and apply the identical to be able to obtain particular information. DEiXTo is a simple and feature rich internet data extracting software. It was originally out there as an extension for Firefox, however is now available for Chrome and IE as nicely. This is a very simple extension that permits you to “educate” what to scrape and the way to scrape. A frequent use case is to fetch the URL of a link, as you did above. Run the above code snippet and also you’ll see the textual content content material displayed. Since you’re now working with Python strings, you'll be able to .strip() the superfluous whitespace. This is especially true should you need massive amounts of data from web sites that are often updated with new content. Thankfully, the world presents different methods to use that surfer’s mindset! Instead of trying at the job web site every day, you need to use Python to help automate the repetitive parts of your job search. Automated web scraping can be a answer to hurry up the data assortment course of. You write your code as soon as and it will get the data you want many instances and from many pages. Array of objects to download, specifies selectors and attribute values to pick files for downloading. Scraper makes use of cheerio to pick out html parts so selector could be any selector that cheerio supports. String, absolute path to directory where downloaded information will be saved. How to download web site to present listing and why it's not supported by default - verify right here. In offline browser mode, it downloads web sites for offline viewing and translate all the inner links to native links. Unlike most some other tools, this feature makes it attainable so that you can notice if one thing isn't working as you anticipated it and you might cease the method and remedy the problem. Besides the actual-time presentation of the download course of, Darcy is able to remember and provide to you statistics relating to all your download processes. Plus, you may copy web site downloaded to knowledge storage units, like USB sticks, CD or DVD; the copied websites will work.
Search Engine Scraper and Email Extractor by Creative Bear Tech. Scrape Google Maps, Google, Bing, LinkedIn, Facebook, Instagram, Yelp and website lists.https://t.co/wQ3PtYVaNv pic.twitter.com/bSZzcyL7w0
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
While you were inspecting the page, you discovered that the link is a part of the factor that has the title HTML class. The current code strips away the entire hyperlink when accessing the .textual content attribute of its parent component. As you’ve seen earlier than, .text only incorporates the visible textual content content of an HTML element. To get the actual URL, you want to extract a kind of attributes as a substitute of discarding it. As talked about earlier than, what occurs within the browser just isn't related to what occurs in your script. Using this extension you possibly can create a plan (sitemap) how a web site must be traversed and what should be extracted. Using these sitemaps the Web Scraper will navigate the positioning accordingly and extract all information. CloudScrape also helps nameless information access by offering a set of proxy servers to hide your id. CloudScrape shops your information on its servers for 2 weeks earlier than archiving it. This way they hope to rank highly in the search engine results pages (SERPs), piggybacking on the original page's web page rank. Some scraper sites are created to earn cash through the use of promoting programs. This derogatory time period refers to websites that haven't any redeeming value except to lure guests to the web site for the sole purpose of clicking on ads. This Edureka live session on “WebScraping using Python” will allow you to understand the fundamentals of scraping along with a demo to scrape some details from Flipkart. 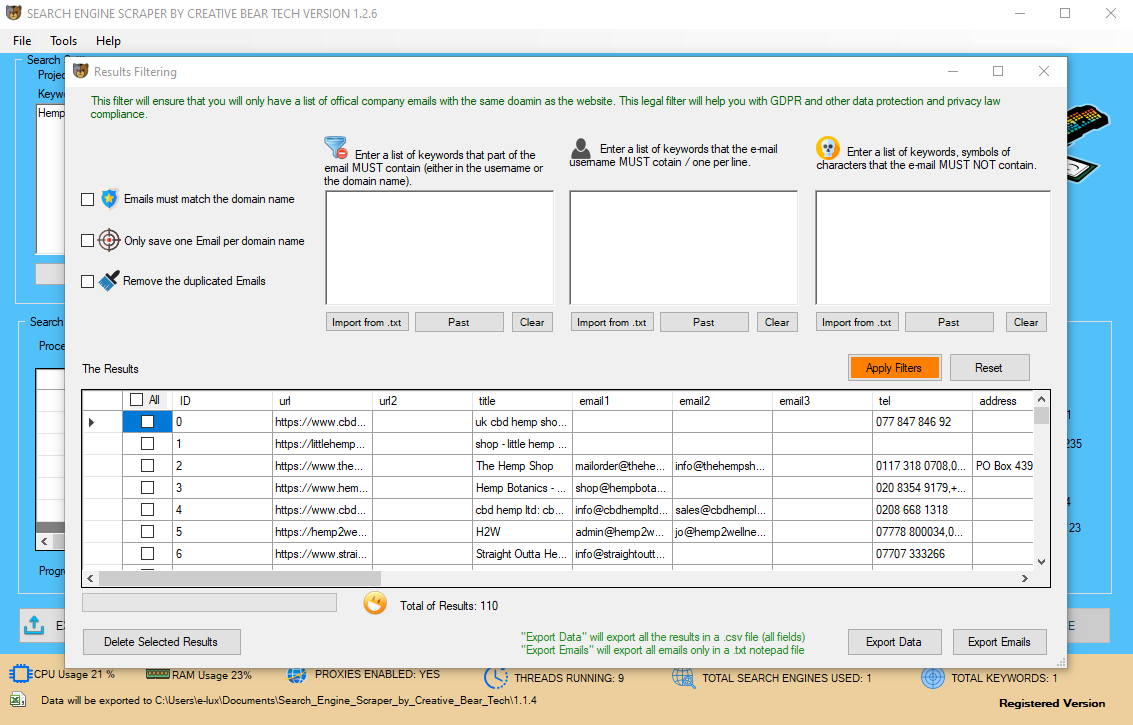 The incredible quantity of information on the Internet is a wealthy resource for any subject of analysis or private interest. To effectively harvest that knowledge, you’ll have to turn out to be expert at web scraping. The Python libraries requests and Beautiful Soup are highly effective tools for the job. If you like to be taught with palms-on examples and you've got a basic understanding of Python and HTML, then this tutorial is for you. I cover the basics of all the net technologies you want so as to be an efficient web scraper in my net scraping ebook. I constructed this plugin because I wanted it for my work to extract advanced buildings of information. It can be straightforward to get lost within the code with a lot of sub-nodes. Darcy Ripper is a straightforward Java application that's used to scrape knowledge from web sites. Essentially, you navigate to a web page, carry out the actions that you have to carry out, and this extension will record all that. To make full use of the facility What are some interesting web scraping projects? of this, you possibly can see the recorded script, and edit it as required. A universal HTTP proxy to hide the origin of your internet scrapers, utilizing each datacenter and residential IP addresses. Crawl arbitrary websites, extract structured data from them and export it to formats similar to Excel, CSV or JSON.
The incredible quantity of information on the Internet is a wealthy resource for any subject of analysis or private interest. To effectively harvest that knowledge, you’ll have to turn out to be expert at web scraping. The Python libraries requests and Beautiful Soup are highly effective tools for the job. If you like to be taught with palms-on examples and you've got a basic understanding of Python and HTML, then this tutorial is for you. I cover the basics of all the net technologies you want so as to be an efficient web scraper in my net scraping ebook. I constructed this plugin because I wanted it for my work to extract advanced buildings of information. It can be straightforward to get lost within the code with a lot of sub-nodes. Darcy Ripper is a straightforward Java application that's used to scrape knowledge from web sites. Essentially, you navigate to a web page, carry out the actions that you have to carry out, and this extension will record all that. To make full use of the facility What are some interesting web scraping projects? of this, you possibly can see the recorded script, and edit it as required. A universal HTTP proxy to hide the origin of your internet scrapers, utilizing each datacenter and residential IP addresses. Crawl arbitrary websites, extract structured data from them and export it to formats similar to Excel, CSV or JSON.